
皆さんはGoogle Drive APIを利用したことがありますでしょうか?
最近Google Drive APIを利用する機会があり、その際に提供されているAPIではどうにも解決できない問題に直面しました。
それはサイズの大きなファイルをアップロードすることはできても、ダウンロードすることができないという問題です。
なぜダウンロードできないかというと、Google Driveからファイルをダウンロードする際、対象ファイルは自動的にウィルススキャンされる仕組みとなっているのですが、100MB以上の大きなファイルについてはウィルススキャンの実行に失敗してしまうためです。
APIではなく、ユーザがGoogle Driveに直接アクセスしてファイルをダウンロードする際は、ウィルススキャンの実行不可であることがダイアログメッセージで表示されます。ただし、強制的にダウンロードする選択肢が用意されており、ダウンロードすることが可能になっております。
しかしながら、APIでファイルダウンロードを試みた際は、ファイルダウンロード要求のタイムアウトになってしまいます。
ユーザ操作であれば強制ダウンロードすることができるため、APIにも同様の機能が提供されているだろうと考えておりましたが、そのような仕様は公式リファレンスから読み取ることができませんでした。
色々と検証を重ねた結果、最終的にダウンロードに成功しましたので、備忘録を兼ねてGoogle Driveからサイズの大きなファイルをダウンロードする方法についてご紹介いたします。
もしももっと良い方法が存在しているようであればコメント頂けると幸いです。
大きなサイズのファイルはウィルススキャンエラーになる
以前紹介したGoogle Driveへの接続サンプルではAPIを利用したファイルダウンロードでした。
しかしながら、大きいサイズのファイルをダウンロードする場合、冒頭で記述した通りダウンロードすることができません。
理由としましては、APIでのダウンロードにおいても以下のようなウィルススキャンエラーが発生しているためです。
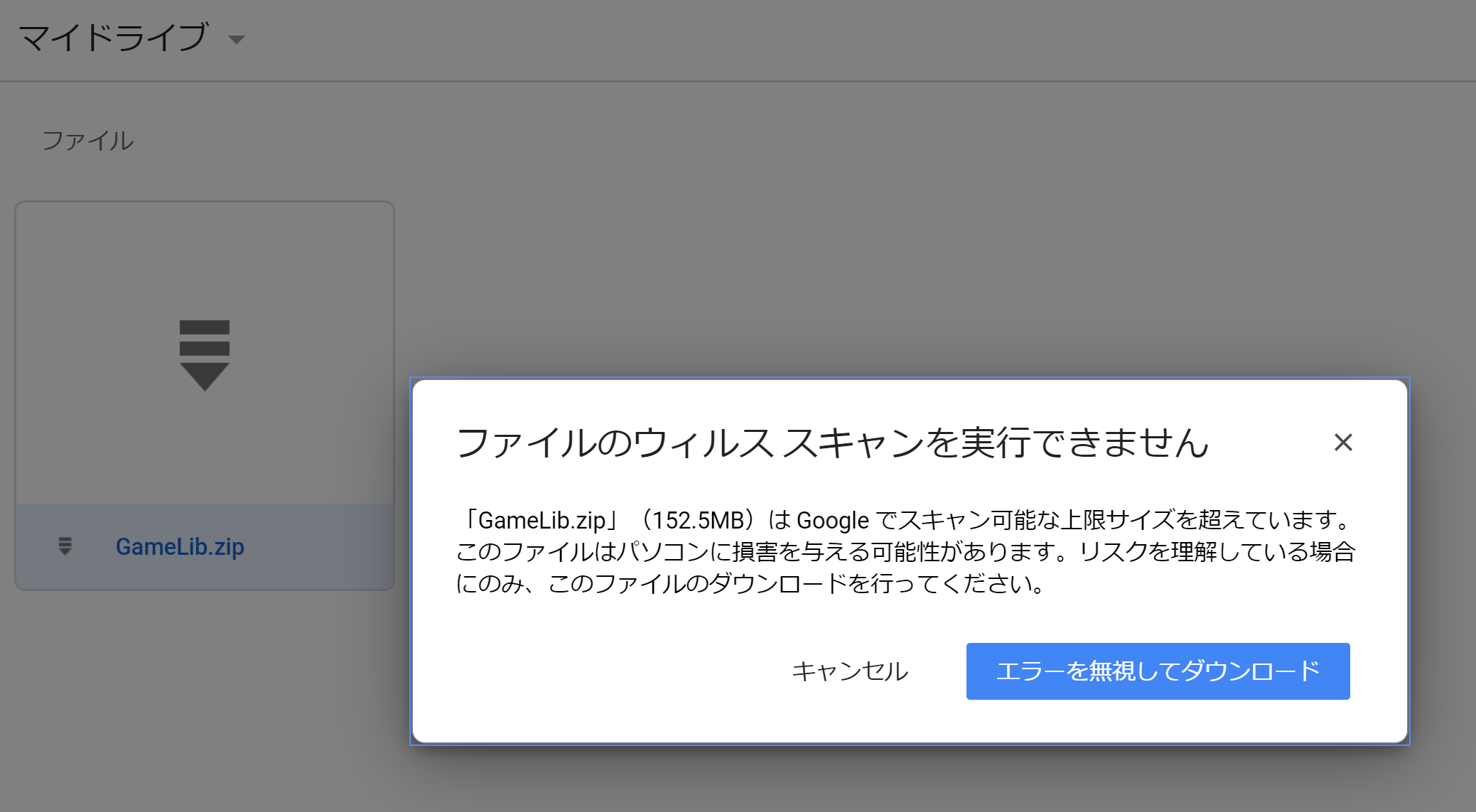
エラーを無視してダウンロードという選択肢があるように、ユーザ操作においてはダウンロードができる仕組みがあるにもかかわらず、API上はありません。
APIからのダウンロードでもユーザ操作と同じようにダウンロードさせることができれば。。。
そんなことを考えて色々検証した結果、上記のダイアログとは別の似たような画面があることが判明致しました。
APIで取得できるファイルのパラメータにwebContentLinkというパラメータがあり、そちらにセットされているURLにアクセスすると、以下のような画面が表示されます。
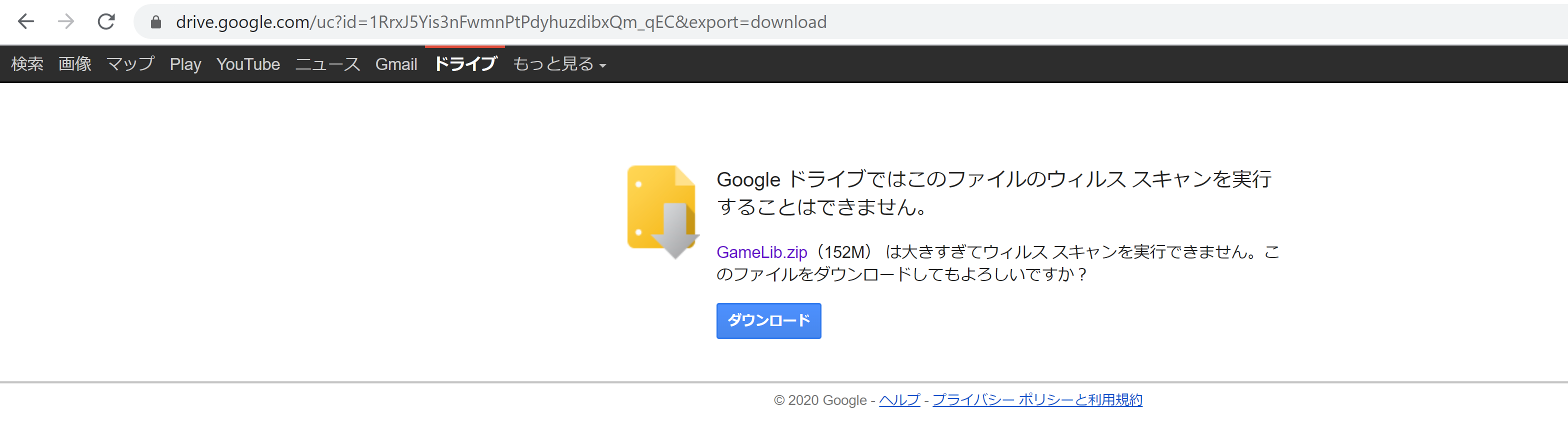
上記画面のダウンロードボタンのパラメータを確認すると、confirmというパラメータに暗号化されたパラメータがセットされていることがわかります。
<a id="uc-download-link" class="goog-inline-block jfk-button jfk-button-action" href="/uc?export=download&confirm=MrZi&id=1RrxJ5Yis3nFwmnPtPdyhuzdibxQm_qEC">ダウンロード</a>
ただし、パラメータはセッション毎に異なりますので、同じセッションでアクセスしなければ変わってしまいます。
また、APIに上記URLを指定してダウンロードを試みても、ユーザ操作向けURLのため、最終的にはログイン画面が表示されて実行できません。
結局使えないのか? と諦めかけていたのですが、もしかするとAPI用のURLにconfirmパラメータだけ追加すればダウンロードできる可能性があります。(入口が違ってもパラメータの処理は共通化されていることを想像して)
そう思って検証したところ、API用のURLのため認証情報が付与されていればログイン画面の表示を回避でき、さらには想像の通りconfirmパラメータのおかげでウイルススキャンエラーを回避して強制ダウンロードすることに成功しました。
JavaでGoogle Driveからサイズの大きいファイルをダウンロードする
ダウンロードに必要な手順は以下の通りです。
(1) Google Drive APIクライアントからDriveへアクセスし、webContentLinkパラメータと有効な認証情報を取得する。
(2) 認証情報をhttpヘッダに追加して、wgetコマンドでwebContentLinkのURLへアクセスする。セッション情報はCookieに保存する。
(3) (2)で取得したhtmlソースからconfirmパラメータを取得する。
(4) Google Drive APIファイルダウンロード用URLにconfirmパラメータを付与し、(2)で保存したCookieをもとにリクエストを実行する。
上記をもとに大きなサイズのファイルダウンロードを実行するサンプルプログラムを作成すると以下のようになります。
※ JavaでGoogle Driveへ接続する方法をご紹介した際のQuickstartにおけるdownloadメソッドを改修しました。(参考:JavaでGoogle Driveに接続する方法)
※ wgetコマンドはリトライとタイムアウトまでの時間を設定できるような形にしています。
build.gradleにライブラリを1つ追加します。
dependencies {
compile 'com.google.api-client:google-api-client:1.23.0'
compile 'com.google.oauth-client:google-oauth-client-jetty:1.23.0'
compile 'com.google.apis:google-api-services-drive:v3-rev110-1.23.0'
// 追加
compile group: 'org.apache.directory.studio', name: 'org.apache.commons.io', version: '2.4'
}
public static String download(Drive service, String fileId, String folderPath, String fileName) {
String ret = null;
if (Objects.isNull(service) || Objects.isNull(fileId) || Objects.isNull(folderPath) || Objects.isNull(fileName)) {
return ret;
}
java.io.File localFolderPath = new java.io.File(folderPath);
if (!localFolderPath.exists()) {
localFolderPath.mkdirs();
}
String filePath = "";
String cookieFileName = fileId + "_cookies.txt";
String cookiePath = "";
String viewFileName = fileId + "_view.txt";
String viewPath = "";
if (Objects.equals(folderPath.substring(folderPath.length()-1), "/")) {
filePath = folderPath + fileName;
cookiePath = folderPath + cookieFileName;
viewPath = folderPath + viewFileName;
} else {
filePath = folderPath + "/" + fileName;
cookiePath = folderPath + "/" + cookieFileName;
viewPath = folderPath + "/" + viewFileName;
}
try {
// API URL
GenericUrl downloadUrl = service.files().get(fileId).setAlt("media").buildHttpRequestUrl();
// File params
File gdfile = service.files().get(fileId).setFields("id, name, size, webContentLink").execute();
// webContentLink URL
String webContentLink = gdfile.getWebContentLink();
// Authorization
HttpRequest httpRequestGet = service.getRequestFactory().buildGetRequest(new GenericUrl(webContentLink));
HttpResponse response = httpRequestGet.execute();
String authHeader = httpRequestGet.getHeaders().getAuthorization();
response.disconnect();
if (Objects.isNull(authHeader)) {
return ret;
}
authHeader = "Authorization: " + authHeader;
String acceptHeader = "Accept: application/json";
// 100MB以上:ウィルススキャンエラー画面が取得される想定, 100MB未満:ログイン画面が取得される想定
String[] wgetCommand1 = {"wget", "--header", authHeader, "--header", acceptHeader, "--quiet", "--save-cookies", cookiePath, "--keep-session-cookies", "--no-check-certificate", webContentLink , "-O", viewFileName};
long timeOut2m = 2 * 60;
processDone(wgetCommand1, localFolderPath, timeOut2m);
java.io.File viewFile = new java.io.File(viewPath);
if (viewFile.exists() && viewFile.length() > 0) {
try (InputStream is = new FileInputStream(viewFile)) {
String content = org.apache.commons.io.IOUtils.toString(is);
Pattern pattern = java.util.regex.Pattern.compile("confirm=[0-9A-Za-z_-]+");
Matcher matcher = pattern.matcher(content);
String nUrl = downloadUrl.toString();
if (matcher.find()) {
// ウィルススキャンエラー画面を取得した場合
String confirmOpt = matcher.group();
nUrl += "&" + confirmOpt;
}
String[] wgetCommand2 = {"wget", "--header", authHeader, "--header", acceptHeader, "--load-cookies", cookiePath, nUrl, "-O", fileName};
// wgetコマンド ファイルダウンロード
long timeOut10m = 10 * 60;
processDone(wgetCommand2, localFolderPath, timeOut10m);
} catch (FileNotFoundException e) {
System.out.println(e.getMessage());
}
}
java.io.File localFile = new java.io.File(filePath);
if (localFile.exists() && localFile.length() > 0) {
ret = filePath;
}
} catch (IOException e) {
System.out.println(e.getMessage());
}
// ファイルダウンロードに成功した場合はファイルパスを返す
return ret;
}
public static void processDone(String[] Command, java.io.File dir, long timeOutSec) {
boolean isFinished = false;
// 外部コマンドに失敗した場合に1回リトライする
for (int i = 0; i<2; i++) {
isFinished = processDoneAux(Command, dir, timeOutSec);
if (isFinished) {
break;
}
}
}
public static boolean processDoneAux(String[] Command, java.io.File dir, long timeOutSec) {
List<String> cmdArray = Arrays.asList(Command);
ProcessBuilder builder = new ProcessBuilder(cmdArray);
// 作業ディレクトリ
builder.directory(dir);
// 標準エラーを標準出力へ統合
builder.redirectErrorStream(true);
// Javaと同じ標準出力に統合
builder.inheritIO();
Process p = null;
boolean isFinished = false;
try {
p = builder.start();
isFinished = p.waitFor(timeOutSec, TimeUnit.SECONDS); // プロセスが正常終了するまで待機
} catch (InterruptedException e) {
System.out.println(e.getMessage());
} catch (IOException e) {
System.out.println(e.getMessage());
} finally {
if (Objects.nonNull(p) && p.isAlive()) {
p.destroy();
}
}
return isFinished;
}
上記であればファイルサイズの大小にかかわらずファイルをダウンロードすることができます。
ただ、Googleの仕様変更によってwebContentLinkのページ構成等が変わったりしてしまうとダウンロードできなくなる可能性があります。
可能ならAPIでforce downloadフラグをONにするとダウンロードできるなど、APIに機能追加して欲しいですね。
まとめ
ダウンロードに必要な手順は以下の通りです。
(1) Google Drive APIクライアントからDriveへアクセスし、webContentLinkパラメータと有効な認証情報を取得する。
(2) 認証情報をhttpヘッダに追加して、wgetコマンドでwebContentLinkのURLへアクセスする。セッション情報はCookieに保存する。
(3) (2)で取得したhtmlソースからconfirmパラメータを取得する。
(4) Google Drive APIファイルダウンロード用URLにconfirmパラメータを付与し、(2)で保存したCookieをもとにリクエストを実行する。
以上です。

